The world creates an immense amount of data every day. From personal photos and videos to scientific research and financial data, the amount of information being created is growing at an exponential rate. However, this growth in data presents a challenge: how do we store all this information efficiently? Compression algorithms offer a solution, allowing us to store large amounts of data in a smaller space.

This summer, my goal is to develop an algorithm that optimizes data compression using Huffman coding. Huffman coding is a form of lossless data compression that uses an optimal prefix code to represent data. The algorithm assigns a unique bit sequence to each symbol in the input data, with more frequently occurring symbols receiving shorter bit sequences. By assigning shorter bit sequences to frequently occurring symbols, the algorithm can reduce the overall size of the data without losing any information.
My project aims to develop an algorithm that will iterate through every possible configuration of the alphabet to determine not only the most compressed version of a text for any given alphabet but will also determine which characters or strings should be included for maximum optimization. I will also develop the code to divide the input text into multiple subtexts with their own uniquely determined optimal alphabets. The order that the text is read and divided will also be analyzed for further development of the algorithm. The final step of the project will involve the analysis of data that has been compressed multiple times using the algorithm to find any correlation between previous compression decisions and the size of the final product.
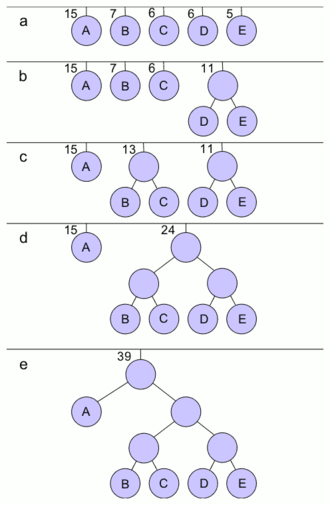
The algorithm I develop has the potential to greatly improve data compression for a variety of applications. From reducing the storage requirements for personal files to improving the efficiency of large-scale data storage systems, my algorithm could have a significant impact on the way we store and access information. Additionally, by developing the code as open-source software, I hope to enable others to build on my work and improve data compression even further.
To accomplish this project, I will be working closely with my supervisor, Prof. Bowers, who is equally as excited about this project as I am. I will be drawing on my background in mathematics, computer science, and physics, which I have developed through my coursework and research projects. I am excited to put my skills and knowledge to the test and to see what new insights I can gain through this project.
One of the key challenges in developing an algorithm for data compression is balancing speed and efficiency. While a highly optimized algorithm may produce the most compressed data, it may take an impractical amount of time to run on large data sets. Conversely, a less optimized algorithm may run quickly but produce suboptimal results. My goal is to retain maximum compression efficiency without wasting large amounts of time computing highly improbable cases for the algorithm to be viable for practical applications with minimal loss of efficiency.

In addition to developing the algorithm itself, I plan to conduct extensive testing to validate its effectiveness. I will use a variety of text files containing ASCII data to test the algorithm’s compression efficiency. I will also test the algorithm on data sets with varying levels of complexity to determine its scalability. By rigorously testing the algorithm, I hope to gain a better understanding of its strengths and limitations, and to identify areas for further improvement.
In conclusion, this project aims to develop an algorithm that optimizes data compression using Huffman coding. The algorithm has the potential to greatly improve data storage and retrieval for a variety of applications. I am excited to see what insights this project will yield, and I look forward to sharing my findings with the academic community.
